


社区推荐算法原理与应用
推荐算法是社区产品内容分发的标配,其精准的推荐效果和商业成功让许多人对个性化推荐近乎迷信。推荐算法包括获取数据、召回、排序和结果展示四个步骤。数据是推荐的依据,包括用户数据和内容数据。召回是从数据库中召回指定数量的内容,排序是对召回的内容做统一的打分排序,结果展示是将排序的结果映射到前端的槽位展示。目前主流的推荐算法有流行度推荐、基于内容推荐和协同过滤这三种逻辑,辅以人群推荐、标签推荐、运营干预等更简单的灵活策略。
热度推荐是根据内容的产生时间、播放、点赞、评论、分享等交互数据计算出时下最流行的内容。其数学原理相对简单,其中包括浏览量、点赞数、评论数、时间因子等。其中,时间因子主要是为了考虑文章热度和创建时间的反比关系,通过指数函数对其进行调控来改变时间因子在对热度的影响。热度推荐常用于技术受限或不需要个性化的社区场景,如B站的【热门】tab,皮皮虾的排行榜等。
如果想要突出新热内容并过滤过时的热门内容,需要增大重力因子。对于周热门和月热门,需要按时间逐渐降小i值。根据不同的变量i取值,热度随时间的衰减趋势会有所不同,具体如下图所示:
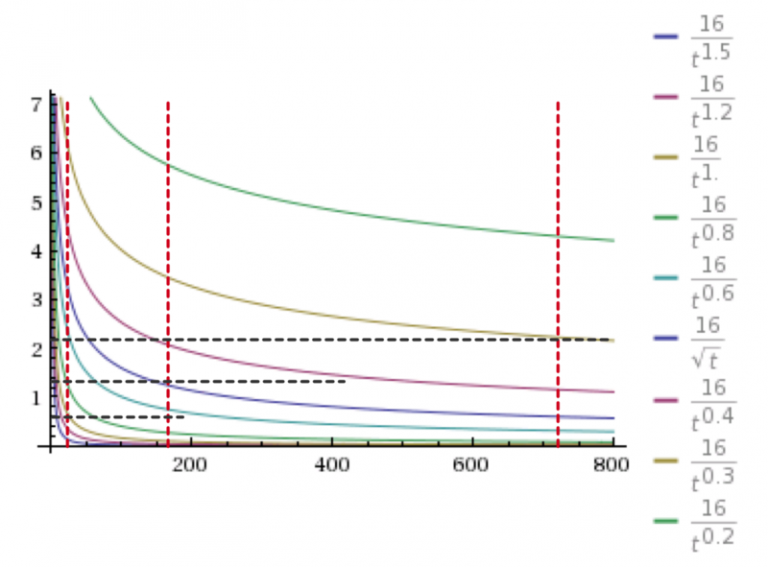
例如,在我所运营的社区话题页面推荐流中,通常按照i=1来计算热度,以此保证内容每天都有新鲜度。但是,当我在做一个每周热门榜单的项目时,就会将i调整为0.5,降低时间衰减的影响,以此保证内容质量。
基于内容推荐是一种推荐算法,它通过识别内容的元数据,在用户浏览或点赞过内容A时,为用户推荐相似的内容B。其原理是识别内容标题、简介、字幕、标签等信息,提取出特征关键词,根据关键词计算内容相似度,以此作为推荐依据。其中最常见的应用场景是电商领域。在淘宝中,当你点击、搜索过某种商品后,算法会将大量的同类商品推荐给你,甚至会在其它平台的广告上展示。但在早期推荐策略比较简单的时候,算法经常会推荐已经买过的商品。
协同过滤是另一种推荐算法,它更加注重发动“群众的智慧”,通过用户群体对不同内容的打分来计算内容的相关性,或猜测用户可能喜欢什么。其中,基于内容的协同过滤根据所有用户对内容的打分,发现内容与内容的相似度,然后再根据用户的历史偏好信息将类似的内容推荐给该用户。打分可以包括播放、点赞、点踩等交互行为,可以是喜欢也可以是不喜欢。例如,甲乙丙是历史偏好信息相近的用户,ABC是不同内容。甲喜欢内容A、内容B、内容C,乙喜欢内容A与内容C,目标用户丙喜欢内容A。由历史偏好可认为内容A与内容C相似,喜欢A的用户可能会喜欢C,以此为依据将内容C推荐给用户丙。而基于用户的协同过滤根据目标用户的历史消费行为,找到与目标用户消费行为相似的近似用户,再以近似用户的喜好为依据向目标用户推荐内容。简而言之,这种方法就是“和你相似的人也喜欢这个”。例如,甲喜欢内容ACD,乙喜欢内容B,目标用户丙喜欢AC。由此可认为用户甲与用户丙的消费喜好是相似的,以此为依据将内容D推荐给用户丙。
推荐算法是非常复杂的,本文也仅停留在概念理解的层面。但可以发现,推荐算法许多工作逻辑同我们运营在做内容分发时的思路是一致的。例如,热度推荐对应推优,基于内容推荐对应专题内容聚合,协同过滤对应精准营销等等。算法可以取代一部分运营的工作,甚至可以比人做得更好。但也有其局限性,例如热度推荐并不能真正理解内容、把控内容导向;协同过滤会使得用户的推荐流越来越垂直,甚至会让用户感到被算法控制。在真正的人工智能时代到来以前,运营策略干预仍然会在内容分发中扮演重要角色,与推荐算法互补共存。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请您通过400-62-96871或关注我们的公众号与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!
























请先 登录后发表评论 ~